# Methodology: Creation and Preprocessing of Datasets
### **Methodology**
### **Creating and Processing of Datasets**
The different datasets can be pre-processed as follows (Table 1):
Textual datasets will undergo tokenisation, stemming, and lemmatization, focusing on physics -related keywords for structural integrity and material properties analysis.
Image datasets will be standardized, converted to grayscale, and normalized. Structural feature extraction will be applied to analyse structural integrity and failures of various structures, while stress-strain graphs will be converted to usable synthetic material data.
In video datasets, we will extract footage segments of structural collapses via sequence formation and encoding to ensure contextual relevance. Spectrograms produced from multiframe audio extraction will undergo Fourier Transforms to produce realistic impact audio effects.
| **Types of Datasets** | **Examples** | | |
| ----------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------- | ------------------------------------------------------------------------------------------------- |
| Material Textures & Structural Properties
(Text, Image)
| 
Figure 2: Different Materials used in Structures
\[7]
| | |
| Stress & Strain Relationships of Materials
(Text, Graph – Image)
| \
Figure 3: Stress-Strain Curve
\[21]
|
| Labelled images of Structures
(Image)
| 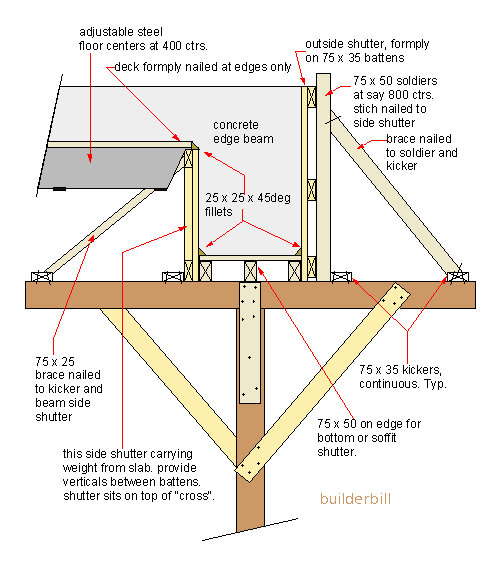
Figure 4: Labelled diagram of Structure
\[3]
| | |
| Live footages of Structures
(Video)
| 
Figure 5: Interstate 35W bridge Collapse
\[18]
| | |
| Game footages of Structures
(Video)
| 
Figure 6: Cities Skyline Game
\[5]
| | |
| Impact Audio
(Audio)
| 
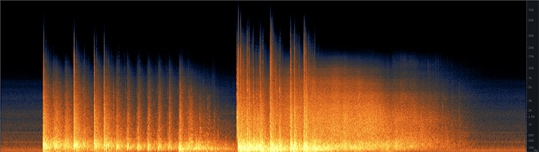
Figure 7: Spectrogram of Implosion of Pasadena State Bank
\[6]
| | |
| Structural Effects of Natural Events
(Text, Video)
| 
Figure 8: Turkey Earthquake Building Collapse
\[2]
| | |
*Table 1: Potential Datasets*